5.1 — Testing Pyramid & Coverage
Listen instead
Learning Objectives
- ✓ Describe each layer of the testing pyramid and justify its cost-to-value ratio.
- ✓ Define and enforce code coverage thresholds appropriate to the organization's risk profile.
- ✓ Explain why coverage metrics alone are insufficient and implement mutation testing.
- ✓ Evaluate AI-generated test cases for quality, completeness, and security relevance.
- ✓ Design a security-specific testing strategy that includes abuse cases, boundary testing, and authorization testing.
 Figure: Testing & Verification Overview — Track 5 coverage of testing strategies, security testing, and verification
Figure: Testing & Verification Overview — Track 5 coverage of testing strategies, security testing, and verification
1. The Testing Pyramid
The testing pyramid is not a suggestion — it is an economic model. Every testing decision is a resource allocation decision. Teams that invert the pyramid (heavy on E2E, light on unit tests) pay exponentially more for slower, flakier, less informative feedback.
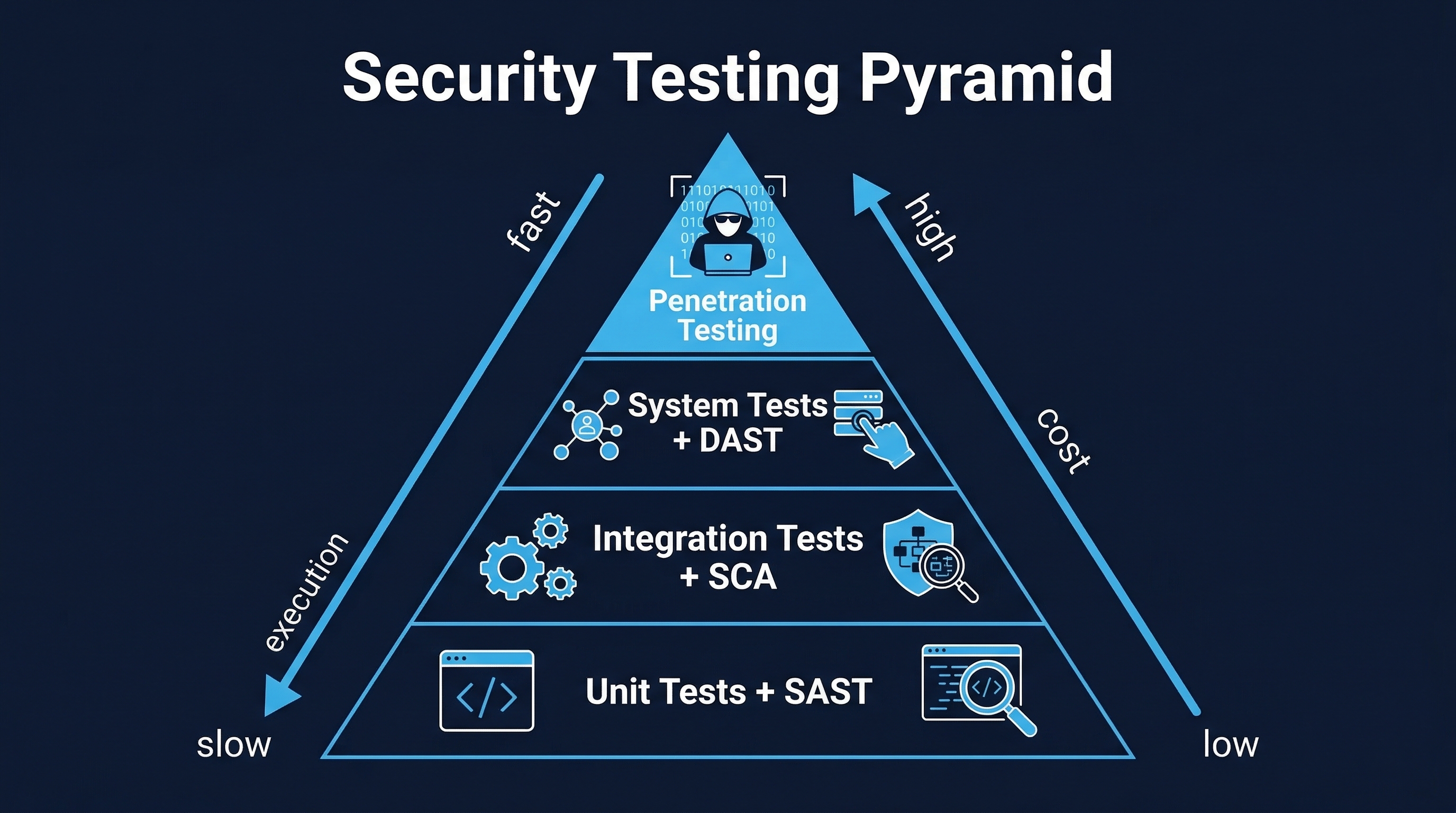 Figure: Security Testing Pyramid — Unit tests (70%), integration tests (20%), and E2E/acceptance tests (10%) with cost-to-value ratios
Figure: Security Testing Pyramid — Unit tests (70%), integration tests (20%), and E2E/acceptance tests (10%) with cost-to-value ratios
1.1 Unit Tests (~70% of Test Suite)
Unit tests validate individual functions, methods, or classes in complete isolation. They are the foundation of the pyramid because they are:
- Fast: Milliseconds per test. A suite of 10,000 unit tests runs in seconds.
- Deterministic: No network, no database, no filesystem. Given the same input, you get the same output every time.
- Cheap to write and maintain: Small scope means small setup, small teardown, small cognitive load.
- Precise in failure diagnosis: When a unit test fails, you know exactly which function broke and often why.
What to unit test:
- Pure business logic (calculations, transformations, validations)
- Edge cases and boundary conditions (null, empty, maximum, minimum, overflow)
- Error handling paths (exceptions, error codes, fallback behavior)
- State transitions (finite state machines, workflow engines)
- Security-relevant logic (input validation, encoding, sanitization functions)
What NOT to unit test:
- Framework glue code (Spring annotations, Express middleware wiring)
- Trivial getters/setters with no logic
- Third-party library internals (that is their responsibility)
- Database queries (those belong in integration tests)
Example — Testing an input validator:
# Function under test
def validate_email(email: str) -> bool:
if not email or len(email) > 254:
return False
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))
# Unit tests
def test_valid_email():
assert validate_email("user@example.com") is True
def test_empty_email():
assert validate_email("") is False
def test_none_email():
assert validate_email(None) is False
def test_email_exceeds_max_length():
assert validate_email("a" * 250 + "@b.co") is False
def test_email_without_domain():
assert validate_email("user@") is False
def test_email_with_special_chars():
assert validate_email("user+tag@example.com") is True1.2 Component Tests
Component tests validate a single service or module with its internal dependencies mocked at the boundary. They sit between unit and integration tests.
- Scope: One microservice, one module, or one bounded context.
- Dependencies: External services are mocked or stubbed. Internal collaborators are real.
- Purpose: Validate internal contracts — that the module’s components work together correctly before introducing external complexity.
Example: Testing an order processing service where the payment gateway is mocked but the internal order validator, pricing calculator, and order repository (in-memory) are real.
Component tests catch the class of bugs that unit tests miss: incorrect wiring between internal collaborators, wrong data transformations between internal steps, and integration assumptions that were never validated.
1.3 Integration Tests (~20% of Test Suite)
Integration tests validate the interaction between multiple services or between a service and its external dependencies. This is where you discover that your assumptions about someone else’s API were wrong.
- Scope: Two or more services interacting, or one service with real external dependencies (database, message queue, third-party API).
- Dependencies: Real infrastructure, either local (Docker Compose, Testcontainers) or shared (test environment).
- Speed: Seconds to minutes per test. Network calls, database transactions, and queue processing all take time.
What integration tests catch that unit tests cannot:
- Serialization/deserialization mismatches (your JSON doesn’t match their JSON)
- Database schema drift (your query assumes a column that was renamed)
- Message format incompatibilities (your producer sends v2, their consumer expects v1)
- Authentication and authorization failures across service boundaries
- Timeout and retry behavior under real network conditions
- Transaction isolation issues (race conditions, deadlocks)
Contract testing is a specialized form of integration testing. Instead of spinning up both services, each side independently verifies against a shared contract (Pact, Spring Cloud Contract). This gives integration-level confidence at unit-test speed.
1.4 System Tests
System tests validate the entire application stack deployed in a production-like environment. They exercise end-to-end business flows across all integrated components.
- Scope: Full stack — UI, API gateway, services, databases, queues, caches, external integrations.
- Environment: Must mirror production in architecture, networking, and security controls. Differences between test and production environments are where production bugs hide.
- Speed: Minutes per test. Environment setup, data seeding, multi-step workflows, and cleanup all contribute.
System tests answer the question: “Does the whole thing work together in an environment that looks like production?” They catch deployment configuration issues, infrastructure mismatches, and cross-cutting concerns (logging, monitoring, security headers) that lower-level tests cannot.
1.5 Acceptance Tests (~10% of Test Suite)
Acceptance tests validate that the system meets business requirements from the user’s perspective. They are the final verification before release.
- Written in business language: Non-technical stakeholders should be able to read and validate them.
- Mapped to requirements: Every acceptance test traces back to a specific user story or business requirement.
- Executed in production-like environment: Same as system tests, but the focus is on business outcomes, not technical behavior.
Behavior-Driven Development (BDD) formalizes acceptance testing:
Feature: Funds Transfer
Scenario: Transfer between accounts with sufficient balance
Given account A has a balance of $1,000
And account B has a balance of $500
When the user transfers $200 from account A to account B
Then account A should have a balance of $800
And account B should have a balance of $700
And a transaction record should be created for both accounts
Scenario: Transfer with insufficient funds
Given account A has a balance of $100
When the user transfers $200 from account A to account B
Then the transfer should be declined
And account A should still have a balance of $100
And the user should see an "Insufficient funds" message2. Cost Economics of Bug Detection
The cost of fixing a defect escalates exponentially the later it is found. This is not theoretical — it is consistently measured across the industry.
| Stage Found | Relative Cost | Why |
|---|---|---|
| Unit test | $1 | Developer fixes immediately, no context switch |
| Integration test | $10 | Multiple components involved, debugging across boundaries |
| System/E2E test | $100 | Full environment, reproduction complex, multiple teams |
| Production | $1,000+ | Incident response, customer impact, rollback, post-mortem |
| Production (security) | $10,000+ | Breach response, regulatory notification, legal, reputation |
Implication: Every dollar spent on unit testing saves $100–$10,000 in downstream costs. This is not an argument for testing only at the unit level — it is an argument for testing at the RIGHT level. Catch what you can early. Use integration and system tests for what unit tests structurally cannot catch.
IBM’s Systems Sciences Institute research and multiple replications show that defects found during requirements are 100x cheaper to fix than defects found in production. The testing pyramid operationalizes this principle.
3. Code Coverage Thresholds
Code coverage measures the percentage of your code that is executed during testing. It is a necessary but insufficient quality metric.
3.1 Coverage Types and Thresholds
| Coverage Type | Standard Threshold | High-Security Threshold | What It Measures |
|---|---|---|---|
| Line coverage | ≥80% | ≥90% | Percentage of executable lines hit during testing |
| Branch coverage | ≥75% | ≥85% | Percentage of decision branches (if/else) exercised |
| Function coverage | ≥85% | ≥95% | Percentage of functions/methods called during testing |
| Critical path | 100% | 100% | Authentication, authorization, payment, data handling |
Line coverage is the most commonly tracked but least informative. A line can be “covered” by a test that never checks the output. Branch coverage is significantly more meaningful because it ensures both sides of every conditional are tested.
Critical path coverage must be 100% — always. There is no acceptable risk threshold for untested authentication logic, authorization checks, payment processing, or personal data handling. If it handles credentials, money, or PII, every path must be tested.
3.2 Enforcing Coverage in CI/CD
Coverage thresholds should be enforced as CI gates, not guidelines:
# Example: pytest with coverage enforcement
- name: Run tests with coverage
run: |
pytest --cov=src --cov-report=xml --cov-fail-under=80
# Example: Jest with coverage enforcement
- name: Run tests with coverage
run: |
npx jest --coverage --coverageThreshold='{"global":{"branches":75,"functions":85,"lines":80}}'Coverage ratcheting is an effective practice: the minimum threshold only ever increases. If coverage is currently at 83%, the gate is set to 83%. New code must not decrease coverage. Over time, coverage naturally increases.
3.3 Why Coverage Alone Is Insufficient
Coverage tells you what code was executed. It does not tell you whether the tests actually validated anything. A test that calls a function and never asserts the result achieves 100% coverage of that function while testing nothing.
Consider this function:
def calculate_discount(price, customer_tier):
if customer_tier == "gold":
return price * 0.8
elif customer_tier == "silver":
return price * 0.9
else:
return priceThis test achieves 100% line and branch coverage:
def test_discount():
calculate_discount(100, "gold")
calculate_discount(100, "silver")
calculate_discount(100, "bronze")But it tests NOTHING. There are no assertions. Every mutation of the business logic (changing 0.8 to 0.9, removing the silver branch entirely, returning 0 for all inputs) would pass this test. Coverage is green. The tests are worthless.
4. Mutation Testing
Mutation testing is the answer to the question: “Do my tests actually detect defects, or do they just execute code?“
4.1 How Mutation Testing Works
- Mutate: The mutation testing tool introduces small, deliberate changes (mutations) to the source code. Each change creates a “mutant.”
- Test: The test suite runs against each mutant.
- Evaluate: If the test suite fails (detects the mutation), the mutant is “killed.” If the test suite passes (misses the mutation), the mutant “survives.”
- Score: The mutation score = (killed mutants / total mutants) × 100%.
Common mutation operators:
| Operator | Original | Mutant |
|---|---|---|
| Conditional boundary | x > 0 | x >= 0 |
| Negate conditional | x == y | x != y |
| Math operator | a + b | a - b |
| Return value | return true | return false |
| Void method call | validate(x) | (removed) |
| Increment/decrement | i++ | i-- |
4.2 Meta’s Research: The Coverage Illusion
Meta’s internal research revealed a devastating finding: code bases with 100% line coverage could have mutation scores as low as 4%. This means 96% of possible defects would not be detected by the test suite, despite the coverage dashboard showing green across the board.
This was not an anomaly. Across the industry, the correlation between line coverage and actual defect detection is weak. Mutation scores in the 20-40% range are common even in well-tested codebases. The gap between “the tests run through the code” and “the tests validate the code” is enormous.
4.3 Mutation Testing Tools
| Tool | Language | Notes |
|---|---|---|
| PIT | Java | Industry standard. Maven/Gradle plugins. Incremental analysis. |
| mutmut | Python | Pure Python. Simple setup. mutmut run and go. |
| Stryker | JavaScript/TypeScript | Comprehensive. Supports React, Angular, Vue. Dashboard. |
| cargo-mutants | Rust | Cargo integration. Fast due to Rust’s type system. |
| mutant | Ruby | Mature. Integrates with RSpec, Minitest. |
4.4 Practical Implementation
Mutation testing is computationally expensive. Running every mutant against the full test suite multiplies test execution time by the number of mutants. Practical strategies:
- Incremental mutation testing: Only mutate changed code (diff-based). PIT supports this natively.
- Sampling: Test a random subset of mutants. Statistically valid at 10-20% sample sizes.
- Targeted mutation: Focus on high-risk code (security logic, financial calculations, authorization).
- CI integration: Run full mutation testing nightly; run targeted mutation testing on every PR.
Target mutation scores:
- General code: ≥40% (baseline), ≥60% (mature)
- Security-critical code: ≥70%
- AI-generated code: ≥60% (mandatory — see Module 5.5)
5. AI-Generated Test Cases
Large language models are transforming test generation. The opportunity is real, but so are the risks.
5.1 Meta’s JiTTest (February 2026)
Meta’s Just-in-Time Testing (JiTTest) system uses LLMs to generate tests at the moment they are needed — when code changes are submitted for review. Key characteristics:
- Hardening tests: Generated to stress-test the specific code being changed, focusing on edge cases and boundary conditions the developer may have missed.
- Regression tests: Generated to capture the current behavior of changed code, ensuring future modifications don’t break existing functionality.
- Scale: Deployed across Meta’s monorepo, generating thousands of tests daily.
- Integration: Tests are suggested during code review, not imposed. Developers can adopt, modify, or reject.
JiTTest represents a fundamental shift: instead of developers writing tests after code (or not at all), the system proactively identifies gaps and generates targeted tests in real time.
5.2 MutGen: Mutation-Guided Test Generation
MutGen combines LLM test generation with mutation testing feedback loops:
- LLM generates initial test cases for a code unit.
- Mutation testing evaluates the generated tests.
- Surviving mutants are fed back to the LLM with the message: “These mutations were not caught. Generate tests that detect them.”
- The LLM generates improved tests targeting the specific gaps.
- Repeat until mutation score reaches the target threshold.
This approach overcomes a fundamental limitation of both LLMs and mutation testing:
- LLMs alone generate tests that look plausible but miss subtle defects.
- Mutation testing alone identifies gaps but cannot generate the tests to fill them.
- Combined, they create a feedback loop that converges on high-quality test suites.
Research shows MutGen achieves 15-30% higher mutation scores than either approach alone.
5.3 LLMs Overcoming Barriers to Mutation Testing
Historically, mutation testing adoption was blocked by two barriers:
- Computational cost: Thousands of mutants × full test suite = hours or days of execution.
- Equivalent mutants: Some mutations produce functionally identical code. Identifying these manually is tedious and error-prone.
LLMs address both:
- Cost: LLMs can predict which mutants are likely to survive (and thus worth testing) without running the full suite. This reduces computation by 60-80%.
- Equivalent mutants: LLMs can analyze mutations and determine semantic equivalence, automatically filtering out false negatives from mutation scores.
5.4 Benefits and Risks of AI-Generated Tests
Benefits:
- Speed: Generate hundreds of test cases in minutes vs. hours/days of manual writing.
- Coverage breadth: AI explores combinations that humans skip due to time constraints.
- Consistency: AI applies the same testing patterns across the entire codebase without fatigue.
- Edge case discovery: LLMs trained on millions of bug reports identify failure patterns humans overlook.
Risks:
- Shallow tests: AI-generated tests often assert that “the function returns something” rather than “the function returns the correct thing.” High coverage, low value.
- Missing edge cases: AI reflects training data. If the training data lacks examples of certain failure modes, the tests won’t cover them.
- Control-flow omissions: AI tests tend to cover happy paths thoroughly and miss error handling, null checks, timeout behavior, and recovery paths.
- Maintenance burden: Poorly generated tests become maintenance debt. Tests that are hard to understand, fragile, or test implementation details (not behavior) slow development.
- False confidence: A green test suite of AI-generated tests can create the illusion of quality while leaving critical gaps uncovered.
Mitigation: Always validate AI-generated tests with mutation testing. If an AI-generated test suite has a mutation score below 40%, it is adding coverage numbers without adding safety.
6. Security-Specific Testing
Standard functional testing validates that the system does what it should. Security testing validates that the system does NOT do what it should not.
6.1 Negative Testing / Boundary Testing
Negative testing intentionally provides invalid, unexpected, or malicious inputs to verify the system handles them safely.
- Null and empty inputs: What happens when every field is null? Empty string? Whitespace only?
- Boundary values: Maximum integer, maximum string length, zero, negative numbers, dates in the past/future.
- Type mismatches: String where integer expected, array where object expected, nested objects 100 levels deep.
- Encoding attacks: URL encoding, double encoding, Unicode normalization, null bytes.
- Oversized inputs: 10MB in a name field, 1 million array elements, deeply nested JSON.
6.2 Abuse Case Testing
Abuse cases are the security equivalent of use cases. For every use case (“User transfers funds”), there are abuse cases (“Attacker transfers funds from victim’s account,” “Attacker transfers negative amount to increase balance,” “Attacker initiates 10,000 transfers simultaneously”).
Structured approach:
- For each use case, enumerate the abuse cases (brainstorm with security team).
- For each abuse case, determine the preconditions (what must be true for the attack to succeed).
- Write tests that attempt each abuse case and verify the system prevents it.
- Include in the test suite and run on every build.
6.3 Race Condition Testing
Race conditions are among the most dangerous and hardest-to-test vulnerabilities. They occur when the outcome depends on the timing of concurrent operations.
Common targets:
- Double-spend: Submit two fund transfers simultaneously, each checking balance independently before either deducts.
- TOCTOU (Time of Check to Time of Use): Check file permissions, then use file — but permissions changed between check and use.
- Inventory oversell: Two users buy the last item simultaneously, both see “1 in stock.”
Testing approaches:
- Thread-based testing: Spawn multiple threads executing the same operation concurrently.
- Request-level testing: Send parallel HTTP requests to the same endpoint.
- Tools: Thread sanitizers (TSAN), race condition detectors (Go’s
-raceflag), Burp Suite Turbo Intruder.
6.4 Error Handling Verification
Error handling is a security boundary. Incorrect error handling leaks information, crashes services, or bypasses security controls.
- Verify stack traces are never exposed to users.
- Verify error messages do not reveal internal implementation details.
- Verify that errors in one component do not cascade to bypass security in another.
- Verify that error states do not leave resources in an unlocked or unprotected state.
- Verify that all catch blocks actually handle the error (not just swallow it silently).
6.5 Authorization Boundary Testing
Authorization testing verifies that access controls are enforced at every layer, not just the UI.
- Vertical privilege escalation: Regular user attempts admin-only operations.
- Horizontal privilege escalation: User A attempts to access User B’s resources.
- API-level bypass: Calling the API directly without going through the UI (which may enforce checks the API does not).
- Parameter manipulation: Changing resource IDs in URLs, request bodies, or headers.
- JWT/token manipulation: Modifying claims, using expired tokens, tokens from different environments.
7. Test Automation Best Practices
7.1 Tests as Code in Version Control
Tests live alongside the code they test. Same repository, same branching strategy, same review process. Tests are not second-class citizens — they are production artifacts.
src/
services/
payment_service.py
tests/
unit/
test_payment_service.py
integration/
test_payment_flow.py
acceptance/
test_purchase_journey.py7.2 Deterministic Tests (No Flaky Tests)
A flaky test is a test that sometimes passes and sometimes fails without any code change. Flaky tests are worse than no tests because they train developers to ignore test failures.
Sources of flakiness and their fixes:
| Source | Fix |
|---|---|
| Time-dependent logic | Inject a clock; never use datetime.now() in tests |
| Random data | Use seeded random generators |
| Shared state | Isolate test data; clean up after each test |
| Network calls | Mock external services; use WireMock/VCR |
| Race conditions | Use synchronization primitives; avoid sleep() |
| Database ordering | Explicitly order results; do not rely on insertion order |
Policy: A test that fails without a code change is quarantined immediately. It is either fixed within 48 hours or deleted. No exceptions.
7.3 Test Independence
Every test must be independent — it must produce the same result regardless of execution order, regardless of which other tests run before or after it.
- No shared mutable state between tests.
- Each test sets up its own preconditions and cleans up its own state.
- Tests can run in parallel without interference.
- Tests can run individually without running the full suite.
7.4 CI Integration
Tests run on every commit, every PR, and every merge. This is non-negotiable.
# Tiered CI test execution
on:
push:
branches: [main, develop]
pull_request:
jobs:
unit-tests:
runs-on: ubuntu-latest
steps:
- run: pytest tests/unit/ --cov --cov-fail-under=80
# Runs in seconds. Blocks merge if failing.
integration-tests:
needs: unit-tests
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16
steps:
- run: pytest tests/integration/
# Runs in minutes. Blocks merge if failing.
mutation-tests:
needs: unit-tests
runs-on: ubuntu-latest
steps:
- run: mutmut run --paths-to-mutate=src/
# Runs nightly. Reports to dashboard. Does not block merge.8. Test-Driven Development (TDD) and Security-TDD
8.1 TDD Cycle
- Red: Write a failing test that describes the desired behavior.
- Green: Write the minimum code to make the test pass.
- Refactor: Clean up the code while keeping all tests green.
- Repeat.
TDD produces code that is testable by design. Every function has at least one test. The test suite grows alongside the code, not as an afterthought.
8.2 Security-TDD
Security-TDD extends TDD by writing security tests first:
- Before writing any authentication code: Write tests that verify unauthenticated requests are rejected, expired tokens are rejected, and invalid tokens are rejected.
- Before writing any authorization code: Write tests that verify users cannot access other users’ resources, regular users cannot access admin endpoints, and deactivated users are denied access.
- Before writing any input handling code: Write tests that verify SQL injection payloads are neutralized, XSS payloads are encoded, and oversized inputs are rejected.
Security-TDD ensures that security requirements are tested from the first line of code. It prevents the common failure mode where security tests are added after development and discover issues that are expensive to fix.
Example — Security-TDD for an API endpoint:
# Step 1: Write security tests FIRST (all should fail initially)
def test_requires_authentication():
response = client.get("/api/accounts/123")
assert response.status_code == 401
def test_prevents_horizontal_access():
response = client.get("/api/accounts/456",
headers=auth_header(user_123))
assert response.status_code == 403
def test_rejects_sql_injection_in_id():
response = client.get("/api/accounts/1' OR '1'='1",
headers=auth_header(user_123))
assert response.status_code == 400
def test_rejects_oversized_id():
response = client.get(f"/api/accounts/{'9' * 10000}",
headers=auth_header(user_123))
assert response.status_code == 400
# Step 2: Implement the endpoint to make all tests pass.
# Step 3: Add functional tests for the happy path.9. Key Takeaways
- The testing pyramid is an economic model. Invest 70% in unit tests, 20% in integration, 10% in E2E. Inverting this ratio multiplies cost and reduces feedback speed.
- Coverage is necessary but insufficient. 100% line coverage means nothing if mutation scores are below 40%. Measure what matters.
- Mutation testing is the real quality gate. It is the only metric that measures whether tests actually detect defects.
- AI-generated tests are powerful but unreliable without validation. Always verify AI tests with mutation testing before trusting them.
- Security testing is not optional. Negative testing, abuse case testing, race condition testing, and authorization boundary testing must be part of every test suite.
- Tests are production code. Version controlled, reviewed, deterministic, independent, and running on every commit.
- Security-TDD makes security testable by design. Write security tests first, then implement the code to pass them.
Review Questions
-
A team has 95% line coverage but a 25% mutation score. What does this tell you about the quality of their test suite, and what specific action should they take?
-
You are reviewing AI-generated test cases for a payment processing module. What three things would you check before approving them for the test suite?
-
Explain why a race condition vulnerability in a funds transfer endpoint would not be caught by standard unit tests. What testing approach would detect it?
-
A developer argues that Security-TDD slows down development. Construct a cost-based argument using the bug-detection cost table.
-
Your CI pipeline runs unit tests on every commit and integration tests nightly. A critical API contract change was merged and not detected until the nightly run. Redesign the pipeline to catch this class of defect earlier without significantly increasing build time.
References
- CIS Controls v8, Safeguard 16.12 — Implement Code-Level Security Checks
- NIST SSDF PW.7 — Review and/or Analyze Human-Readable Code
- Martin Fowler, “The Practical Test Pyramid” (2018)
- Meta Engineering, “JiTTest: Just-in-Time Testing with LLMs” (2026)
- Meta Engineering, “MutGen: Mutation-Guided LLM Test Generation” (2025)
- OWASP Testing Guide v4.2
- PIT Mutation Testing — https://pitest.org
- Stryker Mutator — https://stryker-mutator.io
Study Guide
Key Takeaways
- Testing pyramid is an economic model — Invest 70% unit, 20% integration, 10% E2E; inverting multiplies cost and slows feedback.
- Coverage alone is insufficient — Meta found 100% line coverage with mutation scores as low as 4%, meaning 96% of defects undetected.
- Mutation testing measures real effectiveness — The only metric that confirms tests actually detect defects, not just execute code.
- Defect cost escalates exponentially — $1 at unit test, $10 integration, $100 system, $10,000+ production security.
- AI-generated tests require validation — Often assert “returns something” not “returns the correct thing”; always validate with mutation testing.
- Security-TDD writes security tests first — Before authentication code, write tests verifying unauthenticated/expired/invalid tokens are rejected.
- Flaky tests are worse than no tests — Quarantine immediately, fix within 48 hours or delete. No exceptions.
- MutGen achieves 15-30% higher mutation scores — Combining LLM test generation with mutation testing feedback loops outperforms either alone.
Important Definitions
| Term | Definition |
|---|---|
| Testing Pyramid | Economic model allocating ~70% unit, ~20% integration, ~10% E2E tests |
| Mutation Testing | Introduces deliberate code changes (mutants) to verify tests detect defects |
| Mutation Score | Percentage of killed mutants over total mutants |
| Taint Analysis | Tracks untrusted input from source through transformations to sink |
| Coverage Ratcheting | Minimum coverage threshold only ever increases over time |
| Security-TDD | TDD extended to write security tests before implementing security code |
| MutGen | LLM + mutation testing feedback loop for targeted test generation |
| Component Test | Validates a single service/module with external dependencies mocked |
| Contract Testing | Each side independently verifies against a shared API contract |
| Flaky Test | Test that fails intermittently without code change; quarantined immediately |
Quick Reference
- Coverage Thresholds: Line >=80%, Branch >=75%, Function >=85%, Critical path 100%
- Mutation Score Targets: General >=40%, AI-generated >=60%, Security-critical >=70%
- Cost Multipliers: Unit $1 / Integration $10 / System $100 / Prod $1K+ / Prod Security $10K+
- Common Pitfalls: Inverting the pyramid (heavy E2E), trusting coverage without mutation testing, accepting AI tests without validation, tolerating flaky tests, skipping negative/abuse case testing
Review Questions
- A team has 95% line coverage but 25% mutation score — what does this reveal about test quality and what action should they take?
- How would you design a Security-TDD approach for a payment processing endpoint, and what tests would you write before any implementation code?
- Why can standard unit tests not detect race condition vulnerabilities in a funds transfer endpoint, and what testing approach would?
- How does MutGen’s feedback loop overcome the individual limitations of both LLM test generation and standalone mutation testing?
- Construct a cost-based argument for Security-TDD using the bug-detection cost table when a developer argues it slows development.