2.6 — Privacy by Design
Listen instead
Learning Objectives
- ✓ Apply the seven foundational principles of Privacy by Design to system architecture
- ✓ Map GDPR Article 25 requirements to implementation decisions
- ✓ Conduct Privacy Impact Assessments (PIAs) and Data Protection Impact Assessments (DPIAs)
- ✓ Implement data minimization, purpose limitation, and anonymization techniques
- ✓ Design consent management and data subject rights workflows
- ✓ Evaluate AI coding tool data flows and retention policies for privacy compliance
- ✓ Apply LINDDUN privacy threat modeling to system designs
- ✓ Select appropriate privacy-enhancing technologies (PETs) for specific use cases
1. Seven Foundational Principles of Privacy by Design
Privacy by Design (PbD) was developed by Dr. Ann Cavoukian, former Information and Privacy Commissioner of Ontario, Canada. It was adopted into law by the European Union via GDPR Article 25 and has become the global standard for embedding privacy into system design.
These are not suggestions. Under GDPR, they are legal requirements.
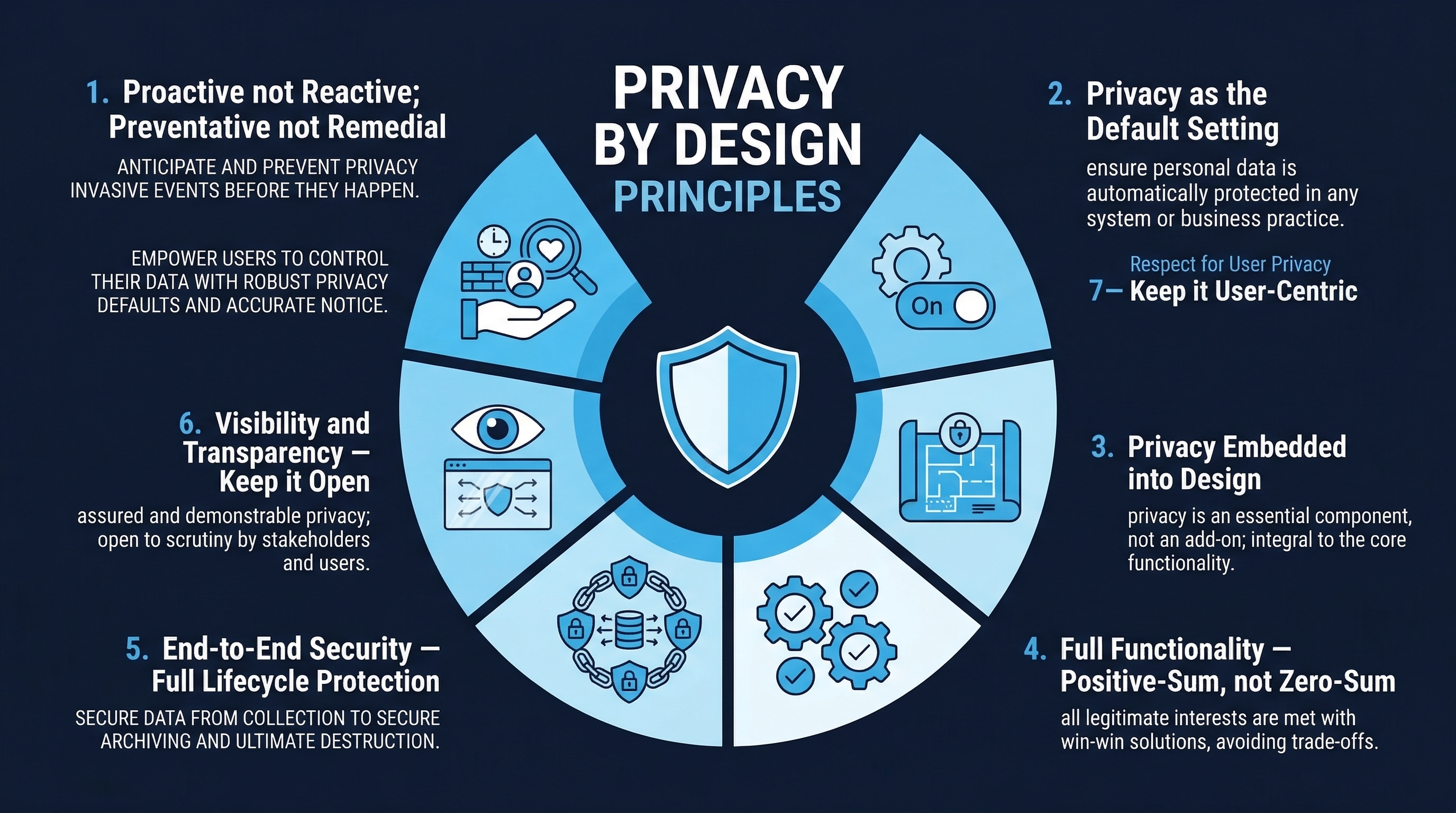 Figure: Privacy by Design Principles — The seven foundational principles for embedding privacy into system design
Figure: Privacy by Design Principles — The seven foundational principles for embedding privacy into system design
Principle 1: Proactive Not Reactive — Preventive Not Remedial
Privacy protections must be built in before the system is deployed, not added after a breach or complaint. Privacy risks are anticipated and prevented. The organization does not wait for privacy incidents to occur and then react.
In practice:
- Privacy requirements are identified during the requirements phase (Module 2.1), not after launch
- Privacy Impact Assessments are conducted during design, not during audit
- Privacy controls are part of the architecture from inception, not retrofitted
- Privacy monitoring detects potential issues before they become breaches
Anti-pattern: “We’ll add a cookie consent banner after we launch.” By then, the system has been collecting data without consent — retroactive consent is not consent.
Principle 2: Privacy as the Default Setting
The system must protect personal data automatically, without any action from the individual. Users should not need to opt out of data collection or adjust settings to protect their privacy. The default is maximum privacy.
In practice:
- Data collection is opt-in, not opt-out
- Privacy settings default to the most restrictive configuration
- Data sharing is disabled by default
- Profile visibility defaults to private
- Location tracking defaults to off
- Analytics defaults to anonymized
Anti-pattern: Signing up for a service and discovering all profile information is public by default, all communications are opted-in by default, and data sharing with partners is enabled by default. The user must navigate multiple settings pages to disable sharing they never consented to.
Principle 3: Privacy Embedded into Design
Privacy is an integral component of the core functionality being delivered. It is not an add-on, a bolt-on, or a separate system. It is woven into the architecture.
In practice:
- Data flows are designed with privacy controls as first-class components
- The database schema reflects data minimization (do not create columns for data you do not need)
- APIs return only the data necessary for the requesting function
- Service boundaries align with data classification boundaries
- Privacy controls are in the same codebase and deployment pipeline as the product
Anti-pattern: A privacy “layer” that sits between the application and the user, attempting to filter out privacy violations from a system that was not designed with privacy in mind. This approach is fragile, incomplete, and maintenance-intensive.
Principle 4: Full Functionality — Positive-Sum, Not Zero-Sum
Privacy by Design rejects the premise that privacy must trade off against functionality, security, or business objectives. It is possible to have full functionality AND full privacy.
In practice:
- Privacy controls enhance user trust, which increases adoption (positive business outcome)
- Anonymized analytics provide business insights without PII exposure
- Pseudonymized data supports debugging and testing without revealing identities
- Privacy-respecting personalization is possible through on-device processing and federated learning
- Security and privacy are complementary, not competing objectives
Anti-pattern: “We can’t implement privacy controls because they’ll reduce our data analytics capabilities.” This framing creates a false dichotomy. Redesign the analytics to work with anonymized data.
Principle 5: End-to-End Security — Full Lifecycle Protection
Personal data must be securely protected throughout its entire lifecycle: from the moment it is collected, through all processing and storage, to its final deletion.
In practice:
- Encryption in transit (TLS 1.2+) for all data collection
- Encryption at rest (AES-256-GCM) for all data storage
- Secure processing environments with access controls
- Data retention policies enforced automatically (data is deleted when the retention period expires, not “whenever someone remembers”)
- Secure deletion that renders data unrecoverable (not just marking records as deleted while retaining the data)
- Backup data subject to the same retention and deletion policies as primary data
Principle 6: Visibility and Transparency
Operations and practices are visible and open to independent verification. Users know what data is collected, how it is used, where it is stored, and who has access.
In practice:
- Clear, plain-language privacy policy (not 40 pages of legal jargon)
- Privacy dashboard showing users what data the system holds about them
- Data processing activities documented and auditable
- Third-party data sharing disclosed with specific recipients named
- Audit logs of data access available for review
- Independent privacy audits and certifications
Principle 7: Respect for User Privacy — Keep It User-Centric
The entire architecture is centered on the individual. Their interests, consent, and autonomy drive design decisions.
In practice:
- Users control their data: access, export, correction, deletion
- Consent is informed, specific, freely given, and easily withdrawable
- Privacy interfaces are usable and accessible (not buried in settings)
- User experience design considers privacy as a core quality attribute
- Support for data portability (users can take their data and leave)
- Grievance mechanisms for privacy concerns
2. GDPR Article 25: Data Protection by Design and by Default
Legal Text (Summarized)
GDPR Article 25 has two components:
Article 25(1) — Data Protection by Design: Taking into account the state of the art, the cost of implementation, and the nature, scope, context and purposes of processing as well as the risks of varying likelihood and severity for rights and freedoms of natural persons, the controller shall, both at the time of the determination of the means for processing and at the time of the processing itself, implement appropriate technical and organizational measures, such as pseudonymization, which are designed to implement data-protection principles, such as data minimisation, in an effective manner and to integrate the necessary safeguards into the processing in order to meet the requirements of this Regulation and protect the rights of data subjects.
Article 25(2) — Data Protection by Default: The controller shall implement appropriate technical and organizational measures for ensuring that, by default, only personal data which are necessary for each specific purpose of the processing are processed. That obligation applies to the amount of personal data collected, the extent of their processing, the period of their storage and their accessibility.
Practical Implementation
| GDPR Requirement | Implementation |
|---|---|
| Data minimization | Collect only necessary fields. Review every data field for necessity. |
| Purpose limitation | Enforce purpose binding in code. Data collected for purpose A cannot be used for purpose B without separate consent. |
| Storage limitation | Automated retention policies. Data expires and is deleted automatically. |
| Pseudonymization | Replace identifiers with pseudonyms. Store mapping separately with strict access controls. |
| Security of processing | Encryption, access controls, monitoring (modules 2.2, 2.4) |
| Default protection | Privacy-protective defaults. No opt-out dark patterns. |
3. Privacy Impact Assessment (PIA) / Data Protection Impact Assessment (DPIA)
When Required
Under GDPR Article 35, a DPIA is mandatory when processing is “likely to result in a high risk to the rights and freedoms of natural persons.” Specifically:
- Systematic and extensive profiling with significant effects on individuals
- Large-scale processing of special categories of data (health, biometric, genetic, racial/ethnic origin, political opinions, religious beliefs, sexual orientation)
- Systematic monitoring of a publicly accessible area on a large scale
- New technologies where the privacy impact is not yet well understood (AI/ML processing falls here)
- Automated decision-making with legal or similarly significant effects
Even when not legally required, PIAs are best practice for any system processing personal data.
DPIA Process
Step 1: Describe the Processing
- What personal data is collected?
- What is the purpose of processing?
- What is the legal basis (consent, legitimate interest, contract, legal obligation)?
- Who processes the data (which teams, which systems, which third parties)?
- Where is the data stored and processed (geographic location)?
- How long is the data retained?
- What data flows exist (collect → process → store → share → delete)?
Step 2: Assess Necessity and Proportionality
- Is the data collection necessary for the stated purpose?
- Could the purpose be achieved with less data?
- Could the purpose be achieved with anonymized data?
- Is the processing proportionate to the benefit?
- What is the legal basis, and is it valid?
Step 3: Identify and Assess Risks For each identified risk, assess:
- Likelihood: How likely is the risk to materialize? (Rare, Unlikely, Possible, Likely, Almost Certain)
- Severity: How severe is the impact on individuals if it materializes? (Negligible, Limited, Significant, Maximum)
- Risk level: Likelihood x Severity matrix
Risk categories to evaluate:
- Unauthorized access to personal data
- Unauthorized modification of personal data
- Loss or destruction of personal data
- Re-identification of anonymized data
- Function creep (data used for unintended purposes)
- Discrimination or bias from automated processing
- Loss of user control over their data
- Chilling effect on behavior due to surveillance
Step 4: Identify Mitigations For each risk, define specific technical and organizational measures:
- Encryption, access controls, anonymization (technical)
- Policies, training, audits, contracts (organizational)
- Privacy-enhancing technologies (PETs)
- Data minimization and purpose limitation controls
Step 5: Document and Approve
- Document the entire DPIA
- Obtain sign-off from the Data Protection Officer (DPO)
- Consult the supervisory authority if residual risk remains high (GDPR Article 36)
- Store the DPIA as part of accountability documentation
Step 6: Monitor and Review
- Review the DPIA when processing changes
- Monitor the effectiveness of mitigations
- Update the DPIA at least annually for high-risk processing
4. Data Minimization
The Principle
Collect only the personal data that is strictly necessary for the specified purpose. Every field, every attribute, every data point must have a documented justification.
Implementation
Collection minimization:
- Review every form field: is this necessary for the function? If not, remove it.
- Do not collect “nice to have” data. Collect only “must have” data.
- If you need aggregate insights, collect aggregated data — not individual records.
- If you need approximate data, collect approximate data — not precise data (zip code instead of full address, age range instead of birth date).
Processing minimization:
- Process only the fields needed for each operation. An analytics pipeline does not need names; a personalization engine does not need home addresses.
- Use views or projections to limit data exposure to each processing component.
- API endpoints return only the fields the caller needs, not the entire entity.
Storage minimization:
- Define retention periods for every data category. Enforce them automatically.
- When the retention period expires, delete the data — not soft-delete, actual deletion.
- Backups must also respect retention periods (data deleted from production should eventually be deleted from backups).
Sharing minimization:
- Share the minimum data necessary with each third party.
- Use tokenization to share references instead of actual data where possible.
- Review all third-party data sharing agreements annually.
Technical Patterns
| Pattern | Implementation |
|---|---|
| Field-level encryption | Encrypt individual PII fields in the database. Only services with the decryption key can access PII. |
| Data masking | Show only partial data in UIs (e.g., ***-**-1234 for SSN, j***@example.com for email). |
| Tokenization | Replace PII with opaque tokens. Detokenization requires access to the token vault. |
| Separate storage | Store PII in a dedicated, hardened data store separate from non-sensitive data. |
| Automated expiry | TTL (time-to-live) on data records. Data automatically deleted after expiry. |
5. Purpose Limitation
The Principle
Personal data collected for one purpose must not be processed for a different purpose without additional legal basis or consent.
Implementation
Purpose binding in architecture:
- Tag data with its collection purpose at the point of collection
- Enforce purpose checks in data access controls: “This service collected data for purpose X. You are requesting it for purpose Y. Access denied.”
- Data access policies reference purpose, not just role
- Audit logs capture the purpose of each data access
Purpose binding in practice:
- Email addresses collected for account authentication cannot be used for marketing without separate consent
- Location data collected for delivery tracking cannot be used for behavioral analytics without separate consent
- Health data collected for treatment cannot be used for insurance underwriting without explicit consent and legal basis
Anti-pattern: A single “terms of service” that grants blanket consent for all current and future processing purposes. GDPR requires specific, informed consent per purpose.
6. Anonymization Techniques
Anonymization removes the ability to identify individuals from the data. Properly anonymized data falls outside GDPR scope (it is no longer personal data). However, true anonymization is difficult — many “anonymized” datasets have been re-identified.
6.1 k-Anonymity
Concept: A dataset satisfies k-anonymity if every combination of quasi-identifiers (attributes that could identify someone in combination, like age + zip code + gender) appears in at least k records.
Example: If k=5, then every combination of (age group, zip code prefix, gender) must appear in at least 5 records. An attacker who knows someone’s age, approximate location, and gender cannot narrow the dataset to fewer than 5 people.
Limitation: k-anonymity does not protect against attribute disclosure. If all 5 people with the same quasi-identifiers have the same disease, the disease is disclosed even though the individual is not identified.
6.2 l-Diversity
Concept: Extends k-anonymity by requiring that within each group of k identical quasi-identifiers, there are at least l distinct values for each sensitive attribute.
Example: In a health dataset with k=5 and l=3, each group of 5 people with identical quasi-identifiers must have at least 3 different diagnoses. This prevents attribute disclosure.
Limitation: Does not protect against skewed distributions. If 4 of 5 people have the same disease and 1 has a different one, the probability of the disease is still very high.
6.3 t-Closeness
Concept: Extends l-diversity by requiring that the distribution of sensitive attributes within each group is close (within threshold t) to the distribution in the overall dataset.
Example: If 10% of the overall population has diabetes, then each anonymity group should have approximately 10% diabetes (within threshold t). This prevents inference from distributional skew.
6.4 Differential Privacy
Concept: Adds calibrated noise to query results or data releases such that the presence or absence of any individual’s data does not significantly affect the output. Provides a mathematical guarantee of privacy.
Parameters: Epsilon (privacy budget) controls the tradeoff between privacy and accuracy. Lower epsilon = more privacy, less accuracy. Typical epsilon values: 0.1 (strong privacy) to 10 (weak privacy).
Use cases:
- Census data releases (US Census Bureau used differential privacy in 2020 Census)
- Analytics dashboards (aggregate counts with noise)
- Machine learning training (differentially private SGD)
- A/B testing (aggregate metrics with privacy guarantees)
Advantage: Mathematical proof of privacy guarantee, unlike k-anonymity which can be broken by auxiliary information.
Limitation: Reduces data accuracy. Not suitable when exact individual records are needed.
7. Pseudonymization
Pseudonymization replaces identifiers with pseudonyms while retaining the ability to re-identify with additional information stored separately. Unlike anonymization, pseudonymized data is still personal data under GDPR, but it is a recognized security measure that reduces risk.
Techniques
| Technique | Reversible | Use Case |
|---|---|---|
| Tokenization | Yes (with token vault) | Credit card numbers, SSNs — replace with opaque token, store mapping in vault |
| Hashing with salt | No (one-way, but linkable if same salt) | De-identification for analytics — same individual produces same hash for linking |
| Keyed HMAC | No (one-way, key-dependent) | Stronger than salted hash — destroying the key prevents re-identification |
| Format-preserving encryption (FPE) | Yes (with key) | When the pseudonym must have the same format as the original (e.g., a fake SSN that looks like a real SSN) |
| Sequential replacement | Yes (with mapping table) | Replace names with “Person 1”, “Person 2” — simple but requires mapping storage |
Key Management for Pseudonymization
The mapping between pseudonyms and real identifiers (token vault, encryption key, mapping table) is the most sensitive component:
- Store separately from pseudonymized data (different database, different access controls, different encryption)
- Restrict access to re-identification capability (need-to-know basis)
- Audit all re-identification operations
- Define a process for permanent de-identification (destroying the mapping when it is no longer needed)
8. Consent Management
Lawful Basis for Processing (GDPR Article 6)
Consent is only one of six lawful bases for processing personal data:
- Consent: Freely given, specific, informed, and unambiguous indication of the data subject’s wishes
- Contract: Processing necessary for the performance of a contract with the data subject
- Legal obligation: Processing necessary to comply with a legal obligation
- Vital interests: Processing necessary to protect someone’s life
- Public interest: Processing necessary for a task carried out in the public interest
- Legitimate interests: Processing necessary for legitimate interests of the controller, balanced against data subject rights
Consent Requirements (When Consent Is the Basis)
- Freely given: The user has a genuine choice. Consent cannot be a condition of service unless the data is necessary for the service. No “consent walls” that block access unless all data collection is accepted.
- Specific: Consent is given for a specific purpose. Blanket consent for “all processing” is not valid.
- Informed: The user is told clearly what data is collected, why, how long it is retained, who it is shared with, and what rights they have.
- Unambiguous: An affirmative action (checkbox tick, button click). Pre-ticked boxes are not valid consent. Silence or inaction is not consent.
- Withdrawable: The user can withdraw consent at any time, and withdrawal must be as easy as giving consent. A “withdraw consent” button, not a 30-day email process.
Consent Architecture
[Consent Collection UI] → [Consent Management Service] → [Consent Database]
↓
[Policy Enforcement Point]
↓
[Data Processing Services]- Consent Collection UI: Clear, specific consent requests with plain-language explanations
- Consent Management Service: Records consent decisions, tracks withdrawal, provides consent status to enforcement points
- Consent Database: Immutable log of all consent events (grant, withdrawal, modification) with timestamps
- Policy Enforcement Point: Checks consent status before allowing data processing. If consent is withdrawn, processing is blocked.
9. Data Subject Rights
GDPR grants individuals the following rights over their personal data. Systems must be architecturally capable of fulfilling these rights.
Right of Access (Article 15)
The data subject can request a copy of all personal data the organization holds about them.
Architecture requirement: The system must be able to locate and export all personal data for a given individual across all data stores, services, and backups. This is often the hardest right to implement in microservices architectures where data is distributed.
Implementation: Personal data index mapping individual identifiers to all data stores containing their data. Automated data subject access request (DSAR) fulfillment pipeline.
Right to Rectification (Article 16)
The data subject can request correction of inaccurate personal data.
Architecture requirement: The system must support updating personal data across all locations where it is stored or replicated. Eventual consistency must converge on the corrected value.
Right to Erasure / Right to Be Forgotten (Article 17)
The data subject can request deletion of their personal data (with certain exceptions).
Architecture requirement: The system must be able to permanently delete all personal data for a given individual from all data stores, replicas, caches, and backups. “Delete” means actual deletion — not soft delete, not marking as inactive.
Challenges:
- Data in backups: must be deleted from backups or excluded when restoring
- Data in distributed systems: deletion must propagate to all replicas
- Data in logs: PII should not be in logs (if it is, log rotation and deletion must cover it)
- Data shared with third parties: the organization must request deletion from third parties
Right to Data Portability (Article 20)
The data subject can request their personal data in a structured, commonly used, machine-readable format and have it transmitted to another controller.
Architecture requirement: Export functionality that produces data in standard formats (JSON, CSV, XML). API for direct transfer to another service when requested.
Right to Object (Article 21)
The data subject can object to processing based on legitimate interests or direct marketing.
Architecture requirement: Processing must stop for that individual upon objection (for the specific processing they object to). This requires per-individual processing controls, not just global on/off switches.
10. Privacy in AI-Augmented Development
AI coding assistants introduce specific privacy concerns that must be addressed in the development process.
10.1 What Data AI Coding Assistants Receive
When a developer uses an AI coding assistant, the tool typically receives:
- Current file content: The file being edited, including any data within it
- Surrounding context: Open files, imported modules, related files in the project
- Prompt/query: The developer’s question or instruction
- Repository metadata: File names, directory structure, language settings
- Conversation history: Previous exchanges in the current session
Privacy concern: If the codebase contains PII (test data with real names, configuration files with credentials, comments referencing real customers), that PII is sent to the AI provider.
10.2 Data Retention Policies by Tool
Understanding what happens to code after it is sent to the AI provider is critical for privacy compliance.
| Tool | Retention Policy | Training Use | Notes |
|---|---|---|---|
| Claude API (Anthropic) | 30-day default, configurable to 0 | No training on API inputs (enterprise) | Enterprise customers can configure zero retention |
| GitHub Copilot Business | Immediate discard | No training on Business/Enterprise tier code | Individual tier: code may be used for training. Business/Enterprise: guaranteed no training. |
| GitHub Copilot Enterprise | Immediate discard | No training | Organizationally isolated. |
| Cursor (Privacy Mode) | Zero retention when enabled | No training | Privacy mode must be explicitly enabled per workspace |
| Amazon CodeWhisperer Professional | No code storage | No training on Professional tier | Individual tier: may use for improvement |
Critical distinction: Individual/free tiers of most AI tools may retain code and use it for training. Enterprise/Business tiers typically guarantee no training and reduced or zero retention. Organizations processing regulated data should use enterprise tiers exclusively.
10.3 PII in Code: Detection and Masking
PII commonly appears in codebases in:
- Test fixtures and seed data (real names, emails, addresses used for testing)
- Configuration files (API keys that contain account identifiers)
- Comments and documentation (customer names, ticket numbers referencing individuals)
- Log formats (templates that include PII fields)
- Database schemas (column comments with example data)
Before sending code to AI assistants:
- Scan for PII using automated tools (detect-secrets, git-secrets, custom regex patterns)
- Replace real PII with synthetic data in test fixtures
- Use environment variables or vault references instead of inline secrets
- Review prompts and context sent to AI assistants for inadvertent PII inclusion
10.4 AI Tool Data Flows and Third-Party Sharing
Map the data flow for each AI tool in your development environment:
[Developer's IDE] → [AI Tool API] → [AI Provider Infrastructure]
↓
[Model Inference]
↓
[Response to Developer]
↓ (if retained)
[Provider's Data Store]
↓ (if used for training)
[Model Training Pipeline]For privacy compliance, you must document:
- What data is transmitted (scope of context sent to API)
- Where it is processed (geographic region of AI provider’s infrastructure)
- How long it is retained (retention policy)
- Whether it is used for model training (training data usage policy)
- Whether it is shared with any third parties (sub-processors)
- What security controls protect it (encryption, access controls)
This documentation should be part of your organization’s Records of Processing Activities (ROPA) under GDPR Article 30.
10.5 Organizational Policy Recommendations
- Use enterprise tiers for all AI coding tools in professional development
- Enable privacy mode or zero-retention settings where available
- Ban free/individual tier AI tools for use on organizational codebases
- Scan code for PII before it is processed by AI tools
- Include AI tools in the organization’s data processing records and DPIA
- Review AI tool agreements as data processor agreements under GDPR Article 28
- Train developers on what data AI tools receive and how to minimize PII exposure
11. LINDDUN Privacy Threat Modeling
LINDDUN (introduced in Module 2.3) provides a structured methodology for identifying privacy threats, analogous to STRIDE for security threats.
LINDDUN Process
- Define the DFD: Create or reuse the data flow diagram from threat modeling (Module 2.3)
- Map LINDDUN to DFD elements: Apply each LINDDUN category to each relevant DFD element
- Identify privacy threats: For each applicable category on each element, describe specific privacy threats
- Prioritize threats: Assess likelihood and impact for each privacy threat
- Define mitigations: Select privacy-enhancing technologies and design patterns to address each threat
- Validate: Verify mitigations are effective
LINDDUN Categories Applied
| Category | Applied To | Example Threat | Example Mitigation |
|---|---|---|---|
| Linking | Data flows, data stores | Attacker correlates anonymized browsing data with purchase history to identify individual | Differential privacy on analytics, purpose separation |
| Identifying | Data stores, processes | Attacker de-anonymizes “anonymous” survey responses using quasi-identifiers | k-anonymity, l-diversity, remove quasi-identifiers |
| Non-repudiation (unwanted) | Processes, data stores | System logs irrefutably link user to sensitive health queries | Privacy-preserving logging, aggregate logs |
| Detecting | External entities, data flows | Attacker detects that a specific user queried an HIV testing service | Encrypted DNS, traffic padding, onion routing |
| Data Disclosure | Data stores, data flows | Unauthorized access to personal health records | Encryption, access controls, audit logging |
| Unawareness | External entities | Users unaware their location is being tracked and shared with advertisers | Transparent privacy policy, privacy dashboard, consent management |
| Non-compliance | Entire system | System retains data beyond stated retention period | Automated retention enforcement, compliance monitoring |
12. Privacy-Enhancing Technologies (PETs)
12.1 Homomorphic Encryption
What it is: Encryption that allows computation on encrypted data without decrypting it first. The result, when decrypted, matches the result of the same computation on the plaintext.
Use case: A cloud provider performs analytics on encrypted health data. They learn the aggregate statistics but never see individual health records.
Current state: Fully homomorphic encryption (FHE) is computationally expensive — orders of magnitude slower than plaintext computation. Partially homomorphic encryption (PHE) is practical for specific operations (addition or multiplication, but not both). Libraries: Microsoft SEAL, IBM HELib, Google’s FHE library.
Practical applicability (2025-2026): Suitable for specific, limited computations (aggregate statistics, simple ML inference). Not yet practical for general-purpose computing.
12.2 Secure Multi-Party Computation (SMPC)
What it is: A protocol that allows multiple parties to jointly compute a function over their combined inputs without revealing their individual inputs to each other.
Use case: Multiple hospitals want to train a disease prediction model on their combined patient data. SMPC allows joint model training without any hospital sharing patient records with the others.
Current state: Practical for specific computations (secure aggregation, set intersection, statistical analysis). Latency and communication overhead make it unsuitable for low-latency applications.
Practical applicability (2025-2026): Suitable for batch processing, periodic model training, collaborative analytics. Not suitable for real-time applications.
12.3 Federated Learning
What it is: A machine learning technique where the model is trained on decentralized data. Data remains on each device/organization, and only model updates (gradients) are shared with a central server.
Use case: Training a keyboard prediction model on user typing data without collecting the actual typing data. Each phone trains locally and shares only the model improvement.
Current state: Deployed at scale by Google (Gboard), Apple (Siri), and others. Libraries: TensorFlow Federated, PySyft, NVIDIA FLARE.
Privacy considerations: Even model gradients can leak information about training data (gradient inversion attacks). Combine with differential privacy (differentially private federated learning) for stronger guarantees.
12.4 Trusted Execution Environments (TEEs)
What it is: Hardware-isolated execution environments (Intel SGX, ARM TrustZone, AMD SEV) where code and data are protected from the operating system, hypervisor, and other processes.
Use case: Processing sensitive data in a cloud environment where the cloud provider cannot access the data, even with administrative access to the host.
Current state: Available on major cloud platforms (Azure Confidential Computing, AWS Nitro Enclaves, GCP Confidential VMs). Practical for many workloads.
Limitations: Side-channel attacks (Spectre/Meltdown variants) have reduced confidence in SGX’s security model. TEEs protect against software attacks but may not fully protect against sophisticated physical or side-channel attacks.
12.5 Zero-Knowledge Proofs (ZKPs)
What it is: A cryptographic protocol that allows one party to prove to another that a statement is true without revealing any information beyond the truth of the statement.
Use case: Prove that you are over 18 without revealing your exact age or date of birth. Prove that your income exceeds a threshold without revealing your exact income.
Current state: Practical for specific use cases (age verification, credential verification, blockchain privacy). Increasingly used in decentralized identity systems.
13. Integration with SDLC
Privacy Requirements in User Stories
Incorporate privacy into user stories using the standard format:
Standard user story: “As a customer, I want to view my order history so that I can track my purchases.”
Privacy-enhanced user stories:
- “As a customer, I want to download all personal data the system holds about me so that I can exercise my right of access.”
- “As a customer, I want to delete my account and all associated data so that I can exercise my right to erasure.”
- “As a customer, I want to see which third parties my data has been shared with so that I can make informed privacy decisions.”
- “As a privacy officer, I want automated data retention enforcement so that personal data is deleted when the retention period expires.”
- “As a developer, I want PII detection in the CI/CD pipeline so that real personal data does not enter test environments.”
Privacy-Focused Code Review Checklist
| Check | Description |
|---|---|
| Data collection | Does this code collect personal data? Is it the minimum necessary? Is there a legal basis? |
| Purpose binding | Is the data used only for the purpose it was collected for? |
| Retention | Is there a defined retention period? Is automated deletion implemented? |
| Access control | Is access to personal data restricted to authorized personnel and services? |
| Encryption | Is personal data encrypted at rest and in transit? |
| Logging | Are logs free of PII? If PII must be logged, is it pseudonymized? |
| Third-party sharing | Does this code send personal data to third parties? Is there a data processing agreement? Is the user informed? |
| Data subject rights | If this code affects data subject rights workflows (access, deletion, portability), does it handle them correctly? |
| Test data | Does this code use real PII in test fixtures? (It should not.) |
| AI tool exposure | If this code was written with AI assistance, was any PII exposed to the AI tool? |
| Consent | Does this code process data that requires consent? Is consent verified before processing? |
Summary
Privacy by Design is not a compliance checkbox — it is an architectural discipline that must be embedded into every phase of the SSDLC. Under GDPR Article 25, it is also a legal requirement.
Key takeaways:
- The seven foundational principles (proactive, default, embedded, positive-sum, end-to-end, visible, user-centric) are the framework for every privacy decision.
- GDPR Article 25 makes Privacy by Design a legal obligation, not optional guidance.
- DPIAs are mandatory for high-risk processing (including AI/ML) and should be conducted during design, not after deployment.
- Data minimization is the most impactful privacy control: data you do not collect cannot be breached, misused, or regulated.
- Anonymization is harder than it appears — k-anonymity, l-diversity, t-closeness, and differential privacy each address different re-identification risks.
- AI coding tools create privacy risks through data exposure — use enterprise tiers, enable privacy modes, scan for PII before AI processing.
- LINDDUN provides a structured approach to privacy threat modeling analogous to STRIDE for security.
- Privacy-enhancing technologies (homomorphic encryption, SMPC, federated learning, TEEs, ZKPs) are maturing but must be evaluated for practical applicability per use case.
- Data subject rights (access, rectification, erasure, portability, objection) must be architecturally supported — they cannot be afterthoughts.
- Privacy code review is as important as security code review — every code change that touches personal data must be evaluated for privacy compliance.
References
- Cavoukian, A. “Privacy by Design: The 7 Foundational Principles” (2009)
- GDPR Article 25: Data Protection by Design and by Default
- GDPR Article 35: Data Protection Impact Assessment
- GDPR Article 6: Lawful Basis for Processing
- GDPR Articles 15-22: Data Subject Rights
- LINDDUN Privacy Threat Modeling Framework (linddun.org)
- NIST SP 800-188: De-Identifying Government Datasets
- NIST Privacy Framework v1.0
- ISO 27701: Privacy Information Management System
- OWASP Top 10 Privacy Risks
- ENISA Guidelines on Data Protection by Design and by Default
- CIS Controls v8, Control 16.10
- NIST SSDF v1.1 — PO.1 (Define Security Requirements)
Study Guide
Key Takeaways
- Seven foundational principles are legal requirements under GDPR — Proactive, default privacy, embedded, positive-sum, end-to-end security, visible/transparent, user-centric.
- GDPR Article 25 mandates data protection by design and by default — Technical measures like pseudonymization and data minimization must be implemented from inception.
- DPIAs are mandatory for high-risk processing — Including AI/ML processing, systematic profiling, large-scale special category data, and automated decision-making.
- Data minimization is the most impactful privacy control — Data you do not collect cannot be breached, misused, or regulated.
- Anonymization is harder than it appears — k-anonymity, l-diversity, t-closeness, and differential privacy each address different re-identification risks.
- AI coding tools create privacy risks — Code context including potential PII is sent to providers; enterprise tiers with zero retention are essential.
- Data subject rights must be architecturally supported — Right of Access (Article 15) is often the hardest to implement in microservices architectures.
Important Definitions
| Term | Definition |
|---|---|
| Privacy by Design | Seven principles by Dr. Ann Cavoukian, adopted into law via GDPR Article 25 |
| DPIA | Data Protection Impact Assessment — mandatory under GDPR Article 35 for high-risk processing |
| k-Anonymity | Every combination of quasi-identifiers appears in at least k records in the dataset |
| l-Diversity | Within each k-anonymity group, at least l distinct values exist for each sensitive attribute |
| Differential Privacy | Adding calibrated noise so any individual’s presence/absence does not significantly affect output |
| Pseudonymization | Replacing identifiers with pseudonyms while retaining re-identification ability — still personal data under GDPR |
| Purpose Limitation | Personal data collected for one purpose must not be processed for a different purpose without additional legal basis |
| LINDDUN | Privacy threat modeling: Linking, Identifying, Non-repudiation, Detecting, Data Disclosure, Unawareness, Non-compliance |
Quick Reference
- Framework/Process: Seven PbD principles; GDPR Articles 6, 15-22, 25, 35; LINDDUN for privacy threat modeling; five PETs (homomorphic encryption, SMPC, federated learning, TEEs, ZKPs)
- Key Numbers: Six lawful bases for processing (Article 6); epsilon parameter controls differential privacy tradeoff; 30-day default retention for Claude API; Rights: access, rectification, erasure, portability, objection
- Common Pitfalls: Adding privacy controls after launch (“cookie consent after the fact”); defaulting to maximum data collection; confusing pseudonymization with anonymization (GDPR still applies to pseudonymized data); logging PII without masking
Review Questions
- What is the key difference between anonymization and pseudonymization under GDPR, and why does it matter for compliance?
- How does the differential privacy epsilon parameter control the privacy-accuracy tradeoff?
- Why is the Right of Access (Article 15) particularly challenging to implement in microservices architectures?
- What privacy risks do AI coding assistants introduce, and how do enterprise tiers mitigate them?
- How would you apply LINDDUN to a healthcare application to identify privacy threats that STRIDE would miss?