3.4 — Secure Code Review
Listen instead
Learning Objectives
- ✓ Explain CIS Control 16.12 requirements and implement static and dynamic analysis in the development lifecycle
- ✓ Execute a four-phase security-focused code review process
- ✓ Apply pull request best practices that maximize defect detection
- ✓ Evaluate AI-powered code review tools and understand their capabilities and limitations
- ✓ Distinguish between traditional SAST and LLM-based SAST approaches and deploy them complementarily
- ✓ Implement human-in-the-loop requirements for AI-assisted security reviews
1. CIS Control 16.12 — Static and Dynamic Analysis
CIS Control 16.12 is classified at Implementation Group 3 (IG3), the highest maturity tier:
Apply static and dynamic analysis tools within the application lifecycle to verify that secure coding practices are being followed.
Why IG3?
This control requires not just having tools, but integrating them into the application lifecycle — meaning they run automatically, their findings are tracked, and they gate deployments. This level of integration requires:
- Tool procurement and configuration
- CI/CD pipeline integration
- Developer training on interpreting and resolving findings
- A triage process for managing false positives and prioritizing fixes
- Metrics and reporting on finding trends
Static Analysis (SAST)
Static Application Security Testing analyzes source code or compiled bytecode without executing the program. It identifies vulnerability patterns through:
- Syntactic analysis: Pattern matching against known vulnerability signatures
- Semantic analysis: Understanding data flow from sources (user input) to sinks (database queries, command execution, HTML output)
- Control flow analysis: Tracing execution paths to find unreachable code, infinite loops, or missing error handling
- Taint analysis: Tracking “tainted” (user-influenced) data through the application to determine if it reaches a dangerous operation without sanitization
Strengths: Finds vulnerabilities early (before the code runs), covers all code paths (not just exercised ones), fast, deterministic, scalable.
Limitations: False positives (flags code that is not actually vulnerable), cannot detect runtime configuration issues, cannot detect business logic flaws, struggles with dynamic language features.
Dynamic Analysis (DAST)
Dynamic Application Security Testing analyzes a running application by sending crafted requests and observing responses.
Strengths: No false positives for confirmed vulnerabilities (if the response demonstrates the vulnerability, it exists), finds runtime issues (misconfigurations, server-side behavior), tests the complete deployed stack.
Limitations: Only tests code paths that are exercised, requires a running environment, slower than SAST, may miss vulnerabilities in unexercised code paths.
Interactive Analysis (IAST)
Interactive Application Security Testing combines SAST and DAST by instrumenting the running application. An agent inside the application monitors data flow in real-time while functional tests execute.
Strengths: Low false positive rate, identifies exact code location of vulnerabilities found at runtime, works with existing test suites.
Limitations: Requires code instrumentation, may impact performance, coverage depends on test comprehensiveness.
Integration into the Lifecycle
Developer Workstation CI Pipeline Staging Production
┌──────────────┐ ┌──────────────────┐ ┌───────────────┐ ┌──────────────┐
│ IDE plugins │ │ SAST scan │ │ DAST scan │ │ RASP │
│ Pre-commit │──────>│ SCA scan │───>│ IAST during │───>│ WAF │
│ hooks │ │ Secrets detection│ │ integration │ │ Runtime │
│ Local lint │ │ License check │ │ tests │ │ monitoring │
└──────────────┘ │ Container scan │ │ Penetration │ └──────────────┘
└──────────────────┘ │ testing │
│ └───────────────┘
│
Merge blocked if:
- Critical/High SAST findings
- Known vulnerable dependencies
- Secrets detected
- License violations2. Why Code Review Matters
Code review is one of the most effective defect detection practices in software engineering. For security specifically:
Multiple Perspectives
Every developer has blind spots. The developer who writes code is optimized for making it work — they think about the happy path, the expected inputs, the normal flow. A reviewer brings an adversarial perspective: what happens with unexpected inputs? What if this assumption is wrong? What if this service is compromised?
Research consistently shows that code review catches 60-70% of defects when performed rigorously. For security defects specifically, review is often the only control that catches business logic vulnerabilities — the kind that SAST tools cannot detect.
Knowledge Sharing
Security code review spreads security knowledge across the team. When a reviewer identifies a vulnerability pattern and explains it, the author learns to avoid that pattern in future code. Over time, this raises the security baseline of the entire team.
Defect Detection Economics
The cost to fix a defect increases by 6-10x at each stage of the development lifecycle:
| Stage | Relative Cost |
|---|---|
| During development (caught by author) | 1x |
| During code review | 1.5x |
| During testing | 6x |
| In staging/QA | 15x |
| In production | 100x |
| After a breach | 1000x+ |
Code review catches defects at the 1.5x stage — by far the most cost-effective point after self-review.
Compliance Evidence
Many compliance frameworks require evidence of code review:
- PCI DSS 4.0 Requirement 6.2.3: Code reviews for custom code changes
- SOC 2: Change management controls include code review
- ISO 27001 A.8.25: Secure development lifecycle requires review processes
- NIST SSDF PW.7: Review and/or analyze human-readable code to identify vulnerabilities and verify compliance
3. Code Review Types
Informal Walkthrough
The author walks one or more reviewers through the code, explaining the design and implementation. This is useful for knowledge sharing but least effective for defect detection because the author controls the narrative.
Use for: Architecture decisions, design pattern explanations, onboarding new team members.
Do NOT use for: Security review of high-risk changes. The author’s explanations can inadvertently bias the reviewer away from vulnerabilities.
Formal Inspection (Fagan Inspection)
A structured process with defined roles (moderator, reader, reviewer, author), preparation time, meeting protocol, and documented findings. Formal inspections have the highest defect detection rate (60-90%) but are time-intensive.
Use for: Critical security components, cryptographic implementations, authentication logic, authorization frameworks.
Pair Programming
Two developers work at one workstation. One writes code (driver), the other reviews in real-time (navigator). Continuous review catches defects as they are introduced.
Use for: Complex security logic, learning/mentoring scenarios, time-sensitive security fixes.
Tool-Assisted Review (Pull Request Review)
The standard modern practice. Code changes are submitted as a pull request, automated tools run checks, and human reviewers examine the diff.
Use for: All code changes. This is the baseline review mechanism for every commit that enters the codebase.
4. Security-Focused Code Review Process
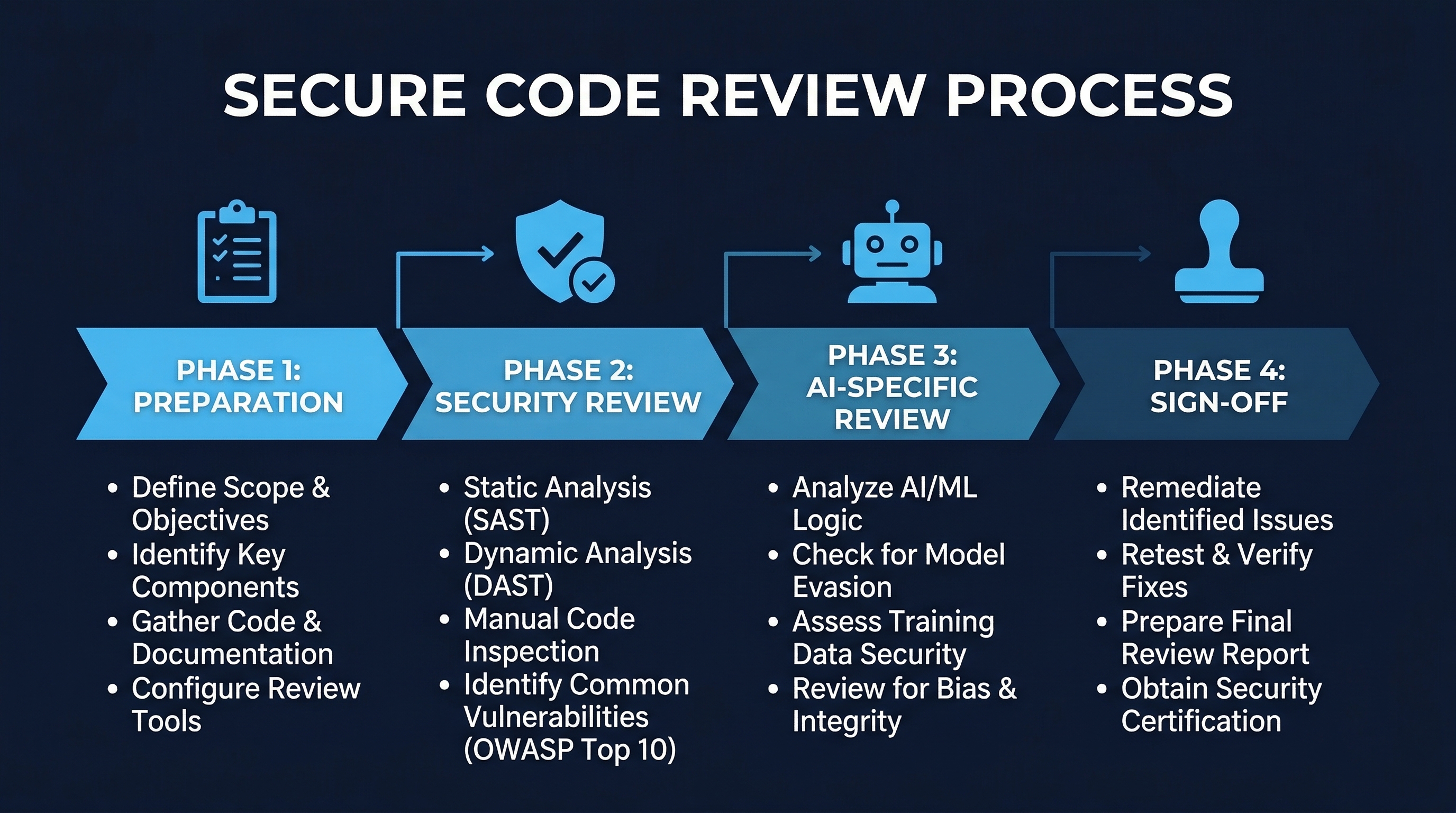 Figure: Secure Code Review Process — Four-phase review workflow from automated pre-review through resolution
Figure: Secure Code Review Process — Four-phase review workflow from automated pre-review through resolution
Phase 1: Automated Pre-Review
Before any human reviews the code, automated checks must pass. These are enforced through CI pipeline status checks that block merging.
Required automated checks:
| Check | Tool Examples | Block on |
|---|---|---|
| Linting | ESLint, Ruff, Checkstyle | Any error |
| Formatting | Prettier, Black, gofmt | Any deviation |
| SAST | Semgrep, CodeQL, SonarQube | High/Critical findings |
| SCA | Snyk, Dependabot, pip-audit | Known CVEs (CVSS 7.0+) |
| Secrets detection | Gitleaks, TruffleHog, git-secrets | Any detection |
| License compliance | FOSSA, license-checker | Blocked licenses |
| Unit tests | Jest, pytest, JUnit | Any failure |
| Coverage | Istanbul, coverage.py | Below threshold (80%+) |
If any of these checks fail, the PR is not eligible for human review. This prevents humans from wasting time reviewing code with known issues and ensures that basic security hygiene is automated.
Phase 2: Security-Focused Review Checklist
Human reviewers should systematically check for security issues beyond what automated tools can detect.
Input Validation:
- All user-controlled input is validated (query params, headers, body, path params)
- Validation uses whitelist approach (what is allowed) not blacklist (what is blocked)
- Validation happens server-side, not just client-side
- File uploads validate content type by magic bytes, not just extension
- Input size limits are enforced
Authentication Logic:
- Authentication checks are present on all non-public endpoints
- Credential comparison uses constant-time comparison
- Error messages do not reveal whether username or password was incorrect
- Session tokens are regenerated after authentication
- Password reset tokens are single-use and time-limited
Authorization Checks:
- Authorization is checked on every request, not just at login
- Object-level authorization verifies the user has access to the specific resource (BOLA prevention)
- Function-level authorization verifies the user has access to the specific operation (BFLA prevention)
- Authorization logic is centralized, not scattered across endpoints
- Privilege escalation paths are not possible
Cryptographic Usage:
- Only approved algorithms are used (no MD5, SHA-1, DES, RC4)
- Encryption uses authenticated modes (GCM, not CBC alone)
- Keys are not hardcoded or stored in source control
- Random values for security use come from CSPRNG
- TLS is enforced for all sensitive data transmission
Error Handling:
- No stack traces, SQL errors, or internal paths in error responses
- All exceptions are caught and handled appropriately
- Error responses use generic messages with correlation IDs
- Resources are freed in error paths (connections, file handles, locks)
Logging of Sensitive Data:
- Passwords are never logged (not even hashed)
- Session tokens are never logged
- PII logging follows data classification policy
- Credit card numbers / SSNs are never logged
- Security events ARE logged: auth failures, authorization denials, input validation failures
Dependency Changes:
- New dependencies are in the approved registry
- Dependency updates do not introduce known vulnerabilities
- Lockfile changes match the declared dependency changes
- No unexpected transitive dependency changes
Phase 3: Human Reviewer Assessment
Beyond the checklist, the human reviewer applies judgment:
- Does the overall design make sense from a security perspective?
- Are there assumptions that could be violated by an attacker?
- Does the code handle adversarial inputs, not just valid inputs?
- Are there TOCTOU (time-of-check-time-of-use) race conditions?
- Does the code maintain the principle of least privilege?
- Are there any business logic vulnerabilities that automated tools cannot detect?
Phase 4: Resolution and Re-Review
- All security findings must be resolved (fixed or explicitly accepted with documented rationale)
- Accepted risks require approval from the security team lead (not just the author’s team lead)
- Changes made to resolve findings require re-review — do not introduce new issues while fixing others
- Stale approvals are automatically dismissed when new commits are pushed
5. Pull Request Best Practices
Size Limits
Target: 200-400 lines of changed code per PR.
Research on code review effectiveness shows a clear correlation between review size and defect detection:
| PR Size (lines changed) | Defect Detection Rate | Reviewer Time |
|---|---|---|
| < 200 | 70-90% | 15-30 min |
| 200-400 | 50-70% | 30-60 min |
| 400-800 | 30-50% | 60-120 min |
| > 800 | 15-30% | Often skimmed |
Beyond 400 lines, reviewer fatigue sets in. Reviewers begin skimming rather than reading. Security vulnerabilities in large PRs are significantly more likely to be missed.
Splitting strategies:
- Separate refactoring from functional changes
- Split by logical unit (one endpoint per PR, one service per PR)
- Front-end and back-end changes in separate PRs when feasible
- Database migration PRs separate from application code PRs
Approval Requirements
- Minimum 2 approvers: Prevents single points of failure in review
- At least 1 CODEOWNER: The CODEOWNERS file designates domain experts. Security-critical paths (auth, crypto, validation) should have security-team CODEOWNERS
- No self-approval: The author cannot be one of the approvers
- No admin override: Branch protection rules should prevent administrators from bypassing review requirements
Review SLA
- Standard changes: 24-hour review SLA
- Security patches: 4-hour review SLA (critical vulnerabilities cannot wait)
- Emergency hotfixes: 1-hour review SLA with post-deployment full review within 24 hours
Additional Controls
- Dismiss stale reviews on new pushes: If a reviewer approves and the author then pushes new commits, the approval is invalidated. The new code must be reviewed.
- Require conversation resolution: All review comments must be marked as resolved before merging. This prevents “comment and ignore” patterns.
- Require linear history: Squash or rebase merges prevent merge commits that obscure the review history.
- Require signed commits: For high-security repositories, require GPG-signed commits to verify author identity.
6. OWASP Code Review Guide Methodology
The OWASP Code Review Guide provides a structured methodology for security-focused code review. Key elements:
Threat-Based Review
Rather than reviewing code line by line hoping to spot vulnerabilities, the reviewer starts with the threat model (from Module 2.3) and reviews code against specific threats:
- Identify the threats relevant to the code under review
- Trace each threat to the code paths that should mitigate it
- Verify that the mitigation is correctly implemented
- Verify that the mitigation cannot be bypassed
Data Flow Analysis
Follow data from external sources through the application:
- Identify all entry points (user input, API calls, file reads, message queue consumers)
- Trace the data through processing, transformation, and storage
- At each point, verify: is the data validated? encoded? sanitized? authorized?
- Identify any points where tainted data reaches a dangerous operation without protection
Common Vulnerability Patterns by Language
Java:
- SQL injection via string concatenation in JDBC:
"SELECT * FROM users WHERE id = " + userId - XXE in XML parsers with default configuration
- Insecure deserialization via
ObjectInputStream - LDAP injection in
javax.namingqueries - Path traversal via
new File(userInput) - Log injection via unsanitized data in log messages (Log4Shell)
Python:
- SQL injection via f-strings or
.format()in queries eval(),exec(),compile()with user inputpickle.loads()/yaml.load()with untrusted data (arbitrary code execution)os.system()andsubprocesswithshell=True- Server-Side Template Injection (SSTI) in Jinja2 with
|safefilter - Path traversal via
os.path.join()with absolute user input (overwrites base path)
JavaScript/TypeScript:
eval(),Function(),setTimeout(string)with user input- Prototype pollution via deep merge with user-controlled objects
- XSS via
dangerouslySetInnerHTML(React) orinnerHTML - SQL injection in template literals with database queries
- ReDoS (Regular Expression Denial of Service) via catastrophic backtracking
- Insecure
postMessagewithout origin checking
Go:
- SQL injection via
fmt.Sprintfin database queries - Path traversal via
filepath.Joinwith user input containing../ - Missing error handling (Go returns errors; unchecked errors hide failures)
- Race conditions in goroutines accessing shared state without synchronization
- HTTP header injection via unsanitized
http.Header.Set()
7. AI-Powered Code Review Tools (2025-2026)
A new generation of code review tools leverages AI for vulnerability detection. These complement but do not replace traditional tools.
Snyk DeepCode AI
Approach: Machine learning models trained on 25+ million data-flow cases from real-world code. Uses symbolic AI combined with deep learning for vulnerability detection.
Strengths:
- Low false positive rate compared to rule-based SAST
- Detects complex data flow vulnerabilities that rule-based tools miss
- Provides fix suggestions based on patterns from successfully remediated code
- Supports 10+ languages with consistent detection quality
Limitations:
- Probabilistic — may miss deterministic patterns that rule-based tools catch
- Requires cloud processing (data leaves your environment unless using Snyk on-premise)
- Detection capabilities depend on training data coverage
Apiiro AI-SAST
Approach: Combines call flow analysis, data flow analysis, reachability analysis, and AI reasoning in a unified engine. The AI component assesses whether a potential vulnerability is actually reachable and exploitable in the application’s context.
Strengths:
- Near-zero false positive rate: if it reports a finding, it is almost certainly real
- Eliminates the “alert fatigue” that plagues traditional SAST
- Understands cross-service data flow in microservice architectures
- Integrates with risk scoring to prioritize findings by business impact
Limitations:
- Requires deep codebase integration for full effectiveness
- Enterprise-only pricing
- May produce false negatives (miss vulnerabilities to maintain low false positive rate)
Aikido Security
Approach: Runs AI-powered security analysis on local servers, ensuring no source code is transmitted to third-party cloud services.
Strengths:
- Data sovereignty: code never leaves the customer’s infrastructure
- Combines SAST, DAST, SCA, container scanning, and IaC scanning in one platform
- AI-powered triage reduces noise by 85%+
- SOC 2 Type II certified
Limitations:
- Requires on-premises infrastructure for the analysis engine
- AI model updates require local deployment
Corgea
Approach: LLM-based analysis specifically designed to detect business logic vulnerabilities — the category of vulnerabilities that traditional SAST tools almost entirely miss.
Strengths:
- Detects logic flaws: race conditions in payment processing, authorization bypass through workflow manipulation, privilege escalation via API parameter tampering
- Generates natural-language explanations of vulnerabilities
- Auto-generates fix suggestions with security rationale
Limitations:
- LLM-based detection is probabilistic and non-deterministic
- May miss straightforward injection patterns that rule-based tools catch reliably
- Relatively new — track record still being established
OpenAI Aardvark / Codex Security
Approach: Agentic code monitoring that continuously analyzes repositories for security issues, using AI agents that autonomously investigate suspicious patterns.
Strengths:
- Agentic approach investigates end-to-end: detects a pattern, traces its implications, verifies exploitability
- Covers both known vulnerability patterns and novel security issues
- Continuous monitoring, not just point-in-time scans
Limitations:
- Autonomous analysis raises concerns about AI making security determinations without human oversight
- Resource-intensive continuous monitoring
- Emergent technology with limited production track record
8. AI SAST vs Traditional SAST
These are complementary approaches, not competitors. Understanding when to use each is critical.
Traditional SAST (Rule-Based)
Mechanism: Pattern matching against a database of rules. Each rule describes a specific vulnerability pattern (e.g., “user input flows to SQL query without parameterization”). Rules are deterministic — the same code produces the same findings every time.
Excels at:
- Compliance checking: Deterministic results required for audit evidence
- Known patterns: CWE Top 25, OWASP Top 10, language-specific vulnerability patterns
- Consistency: Same code, same results, every time — essential for gating
- Speed: Pattern matching is fast, even on large codebases
- Low false negative rate for known patterns: If a rule exists for a vulnerability type, it will find instances
Struggles with:
- Business logic vulnerabilities
- Complex data flow across multiple files/services
- Context-dependent vulnerabilities (is this actually reachable? is there compensating control elsewhere?)
- Novel vulnerability patterns not yet in the rule database
- High false positive rate for some rule categories
LLM-Based SAST (AI-Driven)
Mechanism: Large language models analyze code semantically, understanding the intent and behavior of code rather than matching patterns. The model reasons about what the code does, what could go wrong, and whether the code handles those scenarios.
Excels at:
- Business logic vulnerabilities: Understanding what the code is supposed to do and identifying cases where it does not
- Complex data flow: Tracing data across service boundaries, understanding API contracts
- Novel vulnerability discovery: Can identify vulnerability patterns not in any rule database
- Natural language explanations: Explains why code is vulnerable in terms developers understand
- 0-day discovery: Claude Opus 4.6 has autonomously found 500+ high-severity vulnerabilities in open-source software that had no known CVE
Struggles with:
- Determinism: Same code may produce different results on different runs
- Compliance evidence: Non-deterministic results are harder to use for audit trails
- Known patterns: May miss straightforward injection patterns that a simple rule would catch every time
- Hallucinated findings: May report vulnerabilities that do not actually exist (AI-specific false positives)
- Cost: Token-based pricing makes scanning large codebases expensive
Complementary Deployment
The optimal approach is to run both:
Code Change
│
├─> Traditional SAST (Semgrep, CodeQL, SonarQube)
│ └─ Catches: known patterns, compliance checks,
│ deterministic results for gating
│
├─> LLM-Based SAST (Snyk DeepCode, Apiiro, Corgea)
│ └─ Catches: business logic flaws, complex data flow,
│ novel vulnerabilities, contextual analysis
│
└─> Human Review
└─ Validates both, assesses business context,
makes accept/reject decisions9. GitHub Copilot Code Review Limitations
GitHub Copilot includes code review capabilities, but security testing reveals significant gaps.
What Copilot Review Misses
Research and testing of Copilot’s code review feature for security analysis shows:
- SQL injection: Copilot frequently fails to flag SQL injection even in obvious cases (string concatenation in SQL queries)
- Cross-site scripting: Copilot misses XSS vulnerabilities including direct innerHTML assignment with user input
- Insecure deserialization: Copilot does not reliably detect insecure deserialization of untrusted data
- Broken access control: Copilot rarely identifies missing authorization checks on API endpoints
- Security misconfigurations: Copilot does not flag disabled security features (CSRF protection, CORS misconfiguration)
The Assessment
Copilot’s code review is “not ready to replace dedicated security analysis tools.” It functions well as a code quality reviewer (catching style issues, potential bugs, and performance problems) but lacks the security-specific training and rule sets necessary for security analysis.
Recommendation
- Use Copilot code review for code quality (style, bugs, performance)
- Do NOT rely on Copilot code review for security analysis
- Run dedicated SAST tools (Semgrep, CodeQL) for security detection
- Use specialized AI SAST tools (Snyk DeepCode, Apiiro) for advanced security analysis
- Human security review remains mandatory for security-critical code
10. Human-in-the-Loop Requirements
AI-assisted security review changes the role of the human reviewer but does not eliminate it.
What AI Handles
- Triage: AI scans large volumes of code and flags potential issues, reducing the amount of code humans must review from scratch
- Pattern detection: AI identifies known vulnerability patterns faster and more consistently than human scanning
- Data flow tracing: AI traces data flows across files and services, identifying paths that humans would miss
- Prioritization: AI ranks findings by severity, exploitability, and business impact
- Explanation generation: AI provides natural-language explanations of why code is vulnerable
What Humans Must Validate
- Business logic correctness: Is the authorization model correct for this domain? Does the workflow enforce the right business rules?
- Threat model alignment: Do the security controls match the identified threats?
- Risk acceptance: Is the residual risk acceptable? Should this finding be fixed or accepted?
- False positive adjudication: Is this finding real or a false positive? AI can narrow the field, but humans make the final call.
- Context that AI lacks: Regulatory requirements, organizational policies, customer commitments, pending changes that affect the risk assessment
Human Review Escalation Triggers
These situations ALWAYS require human security review, regardless of AI assessment:
- Authentication logic changes: Any modification to login, logout, MFA, password reset, or session management
- Authorization model changes: New roles, modified permissions, changes to access control enforcement
- Cryptographic changes: Any change to encryption, hashing, key management, or certificate handling
- Third-party integration changes: New external service connections, changed trust boundaries
- Infrastructure-as-code changes: Modified security groups, IAM policies, network rules
- Dependency changes with security implications: Updating security-critical dependencies, adding new ones
- AI-generated code in security-critical paths: Any AI-generated code that handles security functionality
11. Tagging AI-Generated Code in PRs
Identifying AI-generated code in pull requests enables enhanced review scrutiny.
Why Tag?
- AI-generated code has 2.74x higher vulnerability rates — reviewers need to know
- License/IP implications may differ for AI-generated code
- Metrics tracking: measure the security impact of AI tools over time
- Audit trail: demonstrate that AI-generated code received appropriate review
How to Tag
PR description:
## AI Disclosure
- [ ] This PR contains AI-generated code
- AI tool used: [tool name and version]
- Files with AI-generated code: [list files]
- AI-generated code was reviewed per Module 3.2 Trust-but-Verify workflowCommit messages:
feat: add payment refund endpoint
AI-Tool: claude-code
AI-Assisted: trueInline comments (for significant generated blocks):
# AI-GENERATED: Generated by Claude Code, reviewed and modified by [developer]
# Security review: parameterized queries verified, authorization checked,
# input validation confirmed
def process_refund(request: RefundRequest, user: AuthenticatedUser) -> RefundResponse:
...NIST SSDF PW.7
NIST SSDF Practice PW.7 states:
Review and/or analyze human-readable code to identify vulnerabilities and verify compliance with security requirements.
This practice explicitly covers “human-readable code” — which includes AI-generated code. The code’s origin does not change the review requirement. If anything, AI-generated code requires enhanced review given its demonstrated higher vulnerability rate.
12. Summary and Key Takeaways
-
CIS 16.12 requires both static and dynamic analysis in the lifecycle: Not just having tools — integrating them as automated gates that block vulnerable code from merging and deploying.
-
The four-phase review process is mandatory: Automated pre-review, security-focused checklist, human assessment, and resolution/re-review. Skipping any phase creates gaps.
-
PR size directly affects security: Beyond 400 lines, defect detection drops dramatically. Split large changes into reviewable units.
-
AI SAST and traditional SAST are complementary: Traditional catches known patterns deterministically. AI catches business logic and novel vulnerabilities semantically. Run both.
-
Copilot code review is not a security tool: It misses SQL injection, XSS, and insecure deserialization. Do not rely on it for security analysis.
-
Human review is irreplaceable: AI handles triage, pattern detection, and data flow. Humans validate business logic, risk acceptance, and context. Both are required.
-
Tag AI-generated code: Enhanced scrutiny, license tracking, and metrics. Reviewers need to know what they are reviewing.
Lab Exercise
Exercise 3.4: Security Code Review Simulation
Part A: Automated Pipeline Configuration (45 minutes)
Configure a CI pipeline (GitHub Actions YAML) for a sample repository that includes:
- SAST with Semgrep using the
p/owasp-top-tenandp/cwe-top-25rule sets - SCA with pip-audit (Python) or npm audit (Node.js)
- Secrets detection with Gitleaks
- License checking with license-checker
- Branch protection rules that require all checks to pass
Verify the pipeline blocks a PR containing an intentional SQL injection vulnerability.
Part B: Security-Focused Code Review (45 minutes)
Review three pull requests (provided as diffs) using the security-focused checklist from Section 4:
- A PR with subtle authorization bypass (missing object-level check)
- A PR with insecure error handling (leaking internal details)
- An AI-generated PR with multiple issues (outdated library, improper crypto, missing rate limiting)
For each, write review comments that:
- Identify the specific vulnerability
- Cite the CWE ID and OWASP category
- Provide the corrected code
- Explain the security impact if left unfixed
Part C: Tool Comparison (30 minutes)
Run both Semgrep (traditional SAST) and an AI-assisted tool (Snyk Code or similar) on a sample application with 10 intentional vulnerabilities. Document:
- Which vulnerabilities each tool found
- False positive count for each tool
- Time to scan
- Quality of remediation suggestions
- Your recommendation for which to use as the CI gate vs. which to use for deep analysis
Deliverable: CI pipeline YAML, code review comments, tool comparison report Time: 2 hours total
Module 3.4 Complete. Next: Module 3.5 — API Security
Study Guide
Key Takeaways
- CIS 16.12 requires SAST and DAST integrated into the lifecycle — Classified at IG3; tools must gate deployments, not just produce reports.
- Four-phase review process is mandatory — Automated pre-review, security-focused checklist, human assessment, and resolution/re-review.
- PR size directly affects security — 200-400 lines achieves 50-70% defect detection; above 800 lines drops to 15-30% as reviewers skim.
- AI SAST and traditional SAST are complementary — Traditional catches known patterns deterministically; AI catches business logic and novel vulnerabilities semantically.
- Copilot code review is not a security tool — Misses SQL injection, XSS, and insecure deserialization; not ready to replace dedicated SAST tools.
- Human review is irreplaceable for seven escalation triggers — Auth logic, authz model, crypto, third-party integration, IaC, security dependencies, and AI-generated security code.
- AI-generated code must be tagged in PRs — Enables enhanced scrutiny, license tracking, and metrics; NIST SSDF PW.7 applies to all human-readable code regardless of origin.
Important Definitions
| Term | Definition |
|---|---|
| SAST | Static Application Security Testing — analyzes code without executing; uses syntactic, semantic, taint, and control flow analysis |
| DAST | Dynamic Application Security Testing — tests running applications with crafted requests |
| IAST | Interactive Application Security Testing — instruments running applications to monitor data flow during testing |
| Taint Analysis | Tracking user-influenced (“tainted”) data through the application to dangerous operations without sanitization |
| LLM-Based SAST | AI-driven analysis understanding code semantics; detects business logic flaws and novel vulnerabilities |
| CODEOWNERS | File assigning review responsibility based on file paths; security team owns auth, crypto, infrastructure paths |
| NIST SSDF PW.7 | ”Review and/or analyze human-readable code to identify vulnerabilities and verify compliance” |
| Fagan Inspection | Formal structured code review with defined roles; highest defect detection rate (60-90%) |
Quick Reference
- Framework/Process: Four-phase review; OWASP Code Review Guide threat-based methodology; CIS 16.12 (IG3); NIST SSDF PW.7
- Key Numbers: 200-400 lines optimal PR size; minimum 2 approvers; 24-hour standard review SLA; 4-hour security patch SLA; 60-70% defect detection rate for rigorous review; code review catches defects at 1.5x cost
- Common Pitfalls: Reviewing PRs over 800 lines (detection drops to 15-30%); relying on Copilot code review for security; allowing self-approval or admin bypass; dismissing AI SAST as “too many false positives” without trying complementary deployment
Review Questions
- Why does the module recommend running both traditional SAST and LLM-based SAST rather than choosing one?
- What specific vulnerability types does GitHub Copilot code review consistently miss?
- How does threat-based code review (OWASP methodology) differ from line-by-line reading?
- What are the seven escalation triggers that always require human security review regardless of AI assessment?
- How should AI-generated code be tagged in PRs, and what does NIST SSDF PW.7 require?